

Wie das Werkzeug Pixel-to-Points funktioniert
Das Werkzeug Punktwolke aus Bildern (Pixel to Points) im Lidar-Modul von Global Mapper rekonstruiert die 3D-Szene in überlappenden Bildern mithilfe der automatischen Triangulation aus der Luft. Dieser rechenintensive Prozess mag wie Zauberei erscheinen, beruht aber auf grundlegenden Konzepten der Bildverarbeitung und Photogrammetrie. Photogrammetrie ist die Wissenschaft von der Vermessung der realen Welt anhand von Fotos.
Im folgenden Beitrag erläutern wir die grundlegende Verfahrensweise.

Was ist Triangulation aus der Luft?
Auf der Grundlage von Photogrammetrietechniken können Lage, Größe und Form von Objekten aus Fotos abgeleitet werden, die aus verschiedenen Winkeln aufgenommen wurden. Durch die Kombination von Ansichten aus mehreren Bildern wird die Position bestimmter Teile des Bildes im 3D-Raum trianguliert. Dies ist vergleichbar mit der Tiefenwahrnehmung mit zwei Augen: Da das Objekt vor Ihnen aus zwei leicht unterschiedlichen Winkeln betrachtet wird, kann das Gehirn wahrnehmen, wie weit das Objekt entfernt ist.
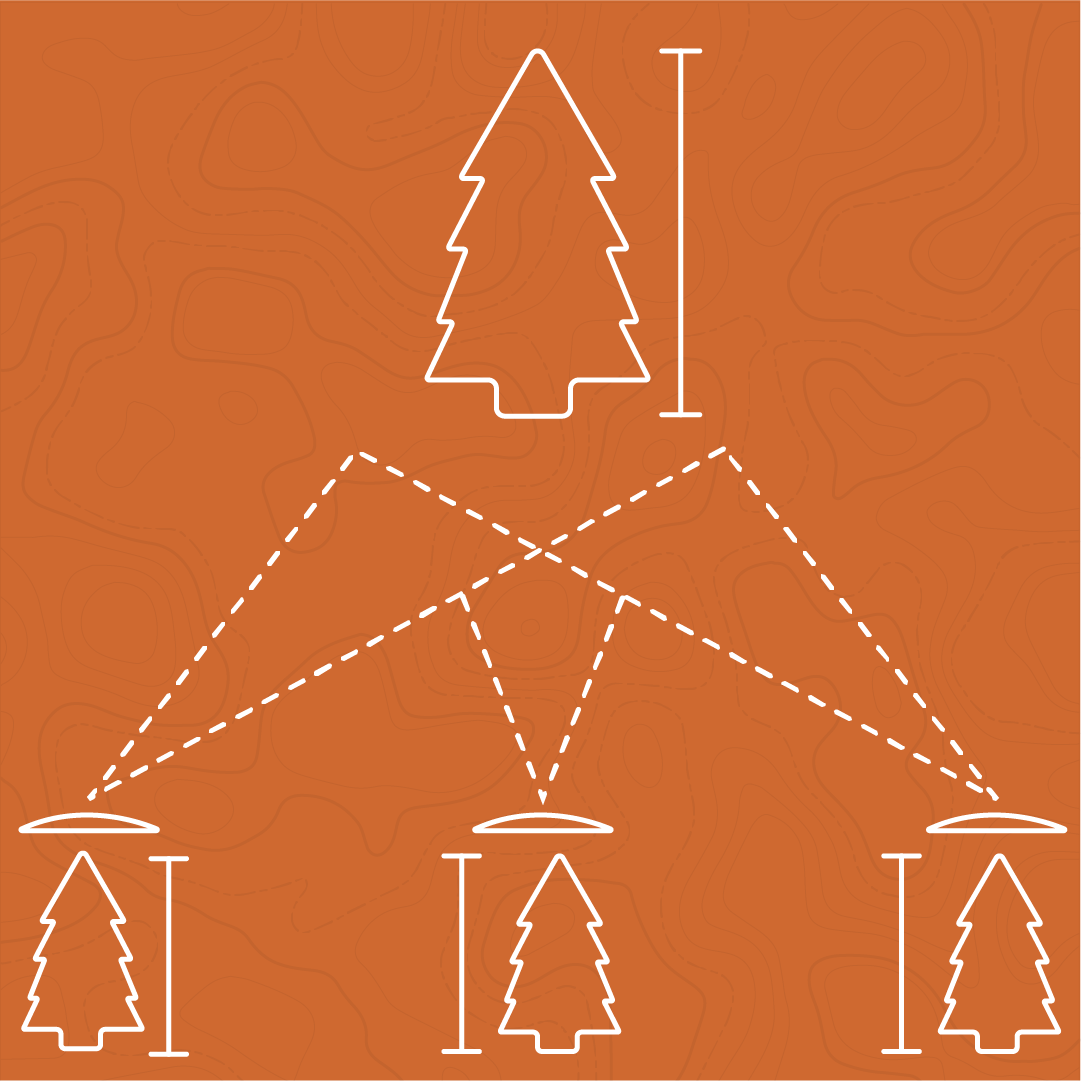
Diagramm der Tiefenwahrnehmung
Bei der traditionellen Photogrammetrie mit Stereobildpaaren kann der Photogrammetriker anhand der beiden Bildwinkel die Objekte im Bild messen und ihre reale Größe bestimmen. Mit automatisierten Techniken, die viele sich überlappende Bilder verwenden, kann die gesamte dreidimensionale Beschaffenheit der fotografierten Szene rekonstruiert werden.

Photogrammetrisches Messdiagramm
Was sind die Schritte bei der automatisierten Triangulation aus der Luft?
Die automatisierte Triangulation aus der Luft umfasst eine Reihe von Schritten, um von den Originalbildern zu 3D-Punktwolken, Geländemodellen, texturierten 3D-Modellen und Orthobildern zu gelangen. Der erste Schritt besteht darin, eindeutige Elemente in jedem Bild zu erkennen und diese Elemente dann mit den benachbarten Bildern abzugleichen. Die Herausforderung besteht darin, automatisch eindeutige Elemente zu erkennen, die in den einzelnen Bildern unterschiedliche Maßstäbe und Drehungen aufweisen können.

In zwei Bildern erkannte Elemente mit Linien, die die gefundenen Übereinstimmungen anzeigen
Nachdem die Elemente durch die Bilder verfolgt wurden, beginnt die erste Rekonstruktion mit einem Verfahren namens Structure from Motion (SfM). Im Zusammenhang mit der Kartierungstechnologie wird die Struktur der 3D-Szene auf der Grundlage der Kamerabewegung ermittelt. Dieser Prozess berechnet die genaue Ausrichtung der Kameras relativ zueinander und zur Szene und baut die grundlegende Oberflächenstruktur der Szene auf.
Dies ist der Punkt, an dem die ausgewählte Analysemethode angewandt wird. Die inkrementelle Analysemethode beginnt mit einem Satz der am besten übereinstimmenden Fotos und fügt schrittweise die Elemente der nachfolgenden Bilder in die Szene ein, um die 3D-Rekonstruktion zu erstellen. Diese Methode eignet sich gut für Drohnenbilder, die über ein großes Gebiet in einem Gittermuster gesammelt wurden. Die Rekonstruktion beginnt in der Regel in der Nähe des Zentrums der Szene und arbeitet sich dann nach außen vor.
Im Gegensatz dazu werden bei der globalen Methode die Informationen aus allen Bildern zusammengenommen und die Szene auf einmal rekonstruiert. Dies ermöglicht einen schnelleren Prozess, erfordert aber auch ein höheres Maß an Überlappung zwischen benachbarten Bildern. Dies ist empfehlenswert, wenn sich die Bilder auf ein bestimmtes Objekt konzentrieren, z. B. ein Gebäude, insbesondere wenn alle Bilder auf diesen zentralen Bereich oder dieses Objekt ausgerichtet sind.
Das Ergebnis der Analyse Structure from Motion (Struktur aus Bewegung) ist eine dünne Punktwolke, die die Grundstruktur der Szene wiedergibt, und eine Reihe von präzise ausgerichteten Kameras, die zeigen, wo und in welcher Richtung die Bilder relativ zueinander aufgenommen wurden.

Beispiel einer spärlichen Punktwolke mit Kamera-Kegelschnitten
Der letzte Schritt der automatischen Triangulation aus der Vogelperspektive beinhaltet das Einfügen zusätzlicher Details aus jedem Bild, das als Teil der Szene kalibriert wurde. Dieser Vorgang wird als Multiview-Stereo bezeichnet. Dabei wird die Tiefe jedes Teils des Bildes berechnet (d. h. wie weit er von der Kamera entfernt ist), und dann werden diese Tiefenkarten verschmolzen, um die Punkte zu erhalten, die in mehreren Bildern erscheinen.


Tiefenkarte und Vertrauenskarte auf der Grundlage von Überschneidungen mit anderen Bildern
Dieser Prozess erzeugt die endgültige dichte 3D-Punktwolke. Je nach den gewählten Optionen kann eine weitere Verarbeitung erfolgen, um die Punktwolke in eine verfeinerte Maschenoberfläche (3D-Modell) umzuwandeln, die durch Projektion der Bilder darauf fototexturiert wird. Diese Option erzeugt auch das hochwertigste Orthobild, indem Reliefverzerrungen auf der Grundlage der 3D-Netzoberfläche entfernt werden.
Welche Faktoren beeinflussen die automatisierte Triangulation aus der Luft?
Objektiv-Verzerrung
Ein wichtiger erster Schritt im Punktwolke aus Bildern-Verfahren (Pixels to Points) ist die Beseitigung der Objektivverzerrung im Bild. Auch wenn das Foto für das ungeübte Auge wie eine flache Aufnahme des Zielgebiets aussieht, enthalten die meisten Fotos eine gewisse Verzerrung, vor allem am Rand des Bildes, wo die Auswirkungen der Krümmung des Kameraobjektivs zu sehen sind. Pixels to Points entfernt die Verzerrungen im Bild je nach Einstellung des Kameratyps. Die meisten Standardkameras benötigen eine Korrektur der grundlegenden radialen Linsenverzerrung, um eine genaue 3D-Szene zu erstellen. Die Standardeinstellung des Kameratyps, Pinhole Radial 3, korrigiert die radiale Linsenverzerrung (mit 3 Faktoren). In einigen Fällen kann es von Vorteil sein, das Kameramodell Pinhole Brown 2 zu verwenden, das sowohl die radiale als auch die tangentiale Verzerrung berücksichtigt, wenn Objektiv und Sensor nicht perfekt parallel sind.


Bild mit Verzerrung und verarbeitetes unverzerrtes Bild
Einige Kameras haben die Möglichkeit, eine Kalibrierung durchzuführen, die automatisch Verzerrungen im Bild beseitigt. Wenn das Werkzeug Pixel to Point anhand der Bildmetadaten erkennt, dass die Bilder kalibriert wurden, wechselt es zum Kameramodell Pinhole.
Wenn Sie wissen, dass die Verzerrung Ihrer Bilder bereits entweder von der Kamera oder einer anderen Software entfernt wurde, wählen Sie das Kameramodell Pinhole, bei dem keine zusätzliche Verzerrungsentfernung vorgenommen wird. Die letzten beiden Kameratypen berücksichtigen die extremeren Verzeichnungen von Fisheye- oder sphärischen Objektiven. Wählen Sie diese Optionen, wenn sie für Ihre Kamera geeignet sind.
Brennweite und Sensorbreite
Ein wichtiger Bestandteil der Übertragung der Bildinformationen in einen realen Maßstab ist die Kenntnis einiger grundlegender Kamera- und Bildinformationen. Die Werte für Brennweite und Sensorbreite ermöglichen eine grundlegende Berechnung der Größe von Objekten im Bild und damit auch ihrer Entfernung zur Kamera. Anhand dieser Werte wird ein Verhältnis zwischen einer bekannten realen Größe (der Sensorbreite) und dem Pixeläquivalent dieser Größe im Bild berechnet. Dies ist ein Ausgangspunkt für die Rekonstruktion der 3D-Szene. Die Informationen zur Brennweite werden normalerweise in den Metadaten des Bildes gespeichert. Global Mapper enthält eine Datenbank mit Sensorbreiten, die auf dem Kameramodell basieren. Sie werden jedoch möglicherweise nach diesem Wert gefragt, wenn Ihre Kamera nicht in der Datenbank enthalten ist. Sie können diese Informationen vom Gerätehersteller erhalten.
Bild Position
Die Grundposition jeder Kamera wird in der Regel in den Bild-Metadaten (EXIF-Tags) gespeichert. Bei einer Standardkamera wird diese Position von GPS abgeleitet, wobei die durchschnittliche horizontale Genauigkeit innerhalb weniger Meter liegt. Es gibt einige Möglichkeiten, die Genauigkeit der resultierenden Daten zu verbessern, je nach gewünschter Genauigkeit und der Abwägung von Kosten und Zeitaufwand.
Höhenkorrektur
Die in den meisten Kameras enthaltenen GPS-Sensoren können für einige Anwendungen eine ausreichende horizontale Genauigkeit aufweisen. Die entsprechenden Höhenwerte sind jedoch in der Regel weniger genau und basieren auf einem ellipsoiden Höhenmodell. Eine grundlegende Höhenkorrektur kann mit den Optionen für Relative Höhe durchgeführt werden. Dadurch werden die Ausgangshöhen auf der Grundlage der Bodenhöhe verankert, auf der die Drohne gestartet ist (die Höhe des Bodens im ersten Bild). Sie können einen bestimmten Wert eingeben, oder Global Mapper kann den Wert automatisch aus geladenen Geländedaten oder Online-Referenzen (USGS NED oder SRTM) ableiten.
Bodenkontrollpunkte
Eine Möglichkeit zur Korrektur der Position der Ausgabedaten ist die Verwendung von Bodenkontrollpunkten. Dabei handelt es sich um eine Reihe von vermessenen Punkten mit bekannten X-, Y- und Z-Positionen, die gleichmäßig über die Szene verteilt sein sollten. Die Positionen der gemessenen Bodenkontrollpunkte müssen in den entsprechenden Bildern visuell identifizierbar sein. Daher wird üblicherweise eine Reihe von Fadenkreuzen oder Zielmarken verwendet, die vor der Aufnahme der Bilder im gesamten Erfassungsbereich auf dem Boden platziert werden.
Bodenkontrollpunkte können in das Werkzeug Pixel to Points geladen und die entsprechenden Positionen in mehreren Eingabebildern identifiziert werden. Dadurch wird die Szene auf der Grundlage der Kontrollpunkte ausgerichtet, die Vorrang vor den Kamerapositionen haben. Dieses Verfahren ist zeitaufwändiger, wird aber durch einen Prozess rationalisiert, bei dem die Bilder, die jeden Punkt enthalten, hervorgehoben werden. Es ist auch möglich, Bodenkontrollpunkte zu verwenden, nachdem die Ausgabedateien erzeugt wurden. Global Mapper stellt hierfür verschiedene Werkzeuge zur Verfügung, darunter die 3D-Entzerrung und das Lidar-QC-Werkzeug, das auch Informationen zur Bewertung der Genauigkeit liefern kann.
RTK- und PPK-Positionierung
Die Hardwarehersteller bieten Optionen zur Verbesserung der Genauigkeit der Positionsdaten an, indem sie zusätzlich zu den Satelliten mit einer Referenzbasisstation kommunizieren und zusätzliche Korrekturen auf der Grundlage der zum Zeitpunkt der Bilderfassung verfügbaren Informationen vornehmen. Dies umfasst sowohl kinematische Echtzeit- als auch kinematische Nachbearbeitungsoptionen. Bei einigen Systemen werden die genaueren Positionsdaten in die Bild-Metadaten geschrieben, die direkt im Werkzeug Pixel to Points verwendet werden können. In diesem Fall müssen Sie Ihre Bilder in das Werkzeug laden und die Option Bildpositionen aus externer Datei laden verwenden.
Wenn Sie die Variablen und Datenanforderungen für das Werkezueg Pixel to Points und andere SfM-Prozesse verstehen, können Sie Bilder sammeln, die sich besser für die Verarbeitung eignen. Dies wiederum führt zu qualitativ hochwertigeren Ergebnissen für die weitere Geodatenanalyse.
Die neueste Version von Global Mapper Pro enthält mehrere Verbesserungen, von denen sich viele auf das Werkezueg Punktwolken aus Bildern (Pixel to Points) zur Erzeugung von Punktwolken und 3D-Netzen aus Drohnenaufnahmen beziehen.